In a relational database, a column is a vertical group of cells within a table.
It’s also used to describe the vertical group of cells within a result set of a query, or other database objects, such as views, stored procedures, table-valued functions, etc.
In a table, each column is typically assigned a data type and other constraints which determine the type of value that can be stored in that column. For example, one column might email addresses, another might accept phone numbers.
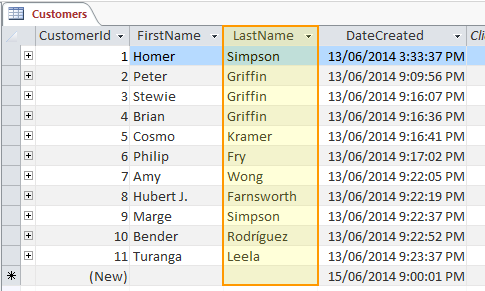
When you create a blank database table, you define the columns along with their data types and any constraints. Therefore, a blank table will contain no rows but will still contain its columns and their constraints. When you add rows (i.e. add data), they can only contain the type of data that has been defined by each column.
The terms column and field are often used interchangeably. However, some experts insist that there is a difference. Teams should determine their own preference and stick with that. If your team determines that column and field mean the same thing, then they can be used interchangeably without fear of misunderstandings arising.
Column Store Databases
The above explanation applies to relational databases.
In certain NoSQL database management systems, a column has a slightly different meaning.
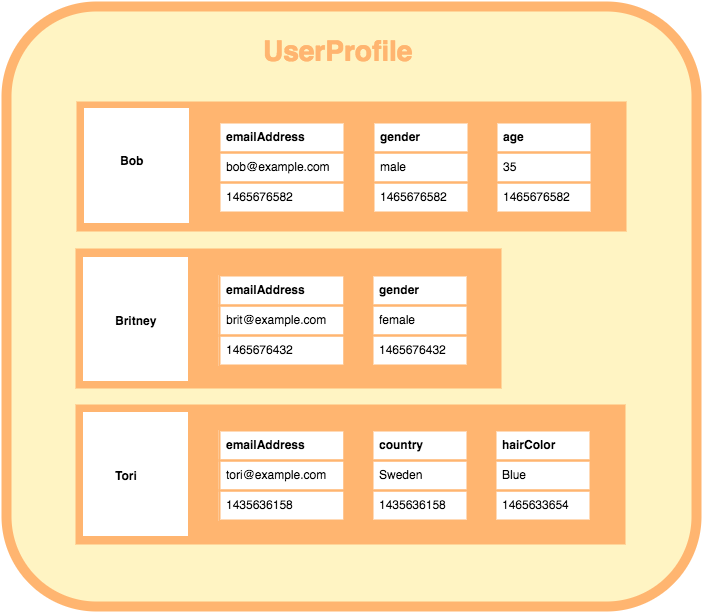
In a column store database, each column contains three properties; a name, a value, and a timestamp. The column doesn’t span all rows in the table (also called column family) like in a relational database. The columns within each row are contained to just that row.
Therefore, each row can contain a different number of columns to the other rows, and the columns need not match the columns in the other rows.
Like this: