The INCLUDE option in SQL Server allows us to include non-key columns in a nonclustered index. These columns are not part of the index key (which SQL Server uses to order and search the index), but they are stored with the index pages.
The INCLUDE option can significantly improve query performance when additional columns are needed by a query but are not part of the index key.
Key vs. Non-Key Columns
The INCLUDE option adds non-key (or nonkey) columns to the nonclustered index, as opposed to key columns. Here’s what we mean by “key” vs “non-key” columns:
- Key columns: These are the columns that make up the index key. The values in these columns are used to organize and search the index efficiently. In a nonclustered index, the key columns are logically sorted and form the index tree.
- Non-key columns: These columns are included with the index but are not used for sorting or organizing. They are essentially added to the leaf nodes of the index and are fetched along with the key columns when the index is accessed.
Why Include Non-Key Columns?
Including non-key columns in an index can avoid the need for key lookups (or bookmark lookups), which occur when SQL Server needs to retrieve additional columns from the base table after using an index. A key lookup involves navigating back to the clustered index (or heap if there’s no clustered index) to retrieve these columns, which can be slow if it happens frequently.
By using the INCLUDE option, we can store the non-key columns directly in the index leaf level, allowing SQL Server to satisfy queries without having to access the base table/clustered index, thus improving query performance. This is often referred to as a covering index; the index has all the columns required to fulfil the query without having to look up the clustered index or heap.
Example
Suppose we create the following table:
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
OrderDate DATE,
OrderAmount DECIMAL(10,2)
);And suppose users frequently use a query that retrieves the OrderID and OrderDate columns based on the CustomerID.
We could create a nonclustered index on CustomerID alone (without the INCLUDE option), but if the query also needs the OrderDate column, SQL Server would have to perform a key lookup to retrieve that additional column from the base table. But if we include the OrderDate column, then it won’t need to do the key lookup. And if OrderDate doesn’t need to be a key column, then we can include it with the INCLUDE option.
Without Including the Column
Here’s an example of creating an index without including the OrderDate column (and without the INCLUDE option):
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_1
ON Orders (CustomerID);Now let’s run the frequently used query that we were discussing, and check the query plan:
SELECT OrderID, OrderDate
FROM Orders
WHERE CustomerID = 123;And here’s the query plan for that query:
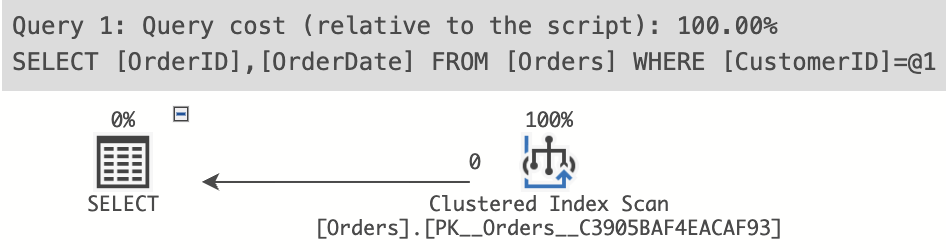
The query didn’t even use our nonclustered index. It did an index scan of the clustered index instead. The query optimizer probably decided that there was no point in using the nonclustered index because it doesn’t contain all required data anyway. So even if it had looked up the nonclustered index, it would also need to do a key lookup in the clustered index to find the OrderDate column. May as well just go straight to the clustered index and grab all data from there.
Include the Column
And here’s how we can use the INCLUDE option to include the extra column:
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_2
ON Orders (CustomerID)
INCLUDE (OrderDate);In this case, the index is created on CustomerID (the key column), but the OrderDate (a non-key column) is included in the index’s leaf nodes.
Now let’s run the query again:
SELECT OrderID, OrderDate
FROM Orders
WHERE CustomerID = 123;Query plan:
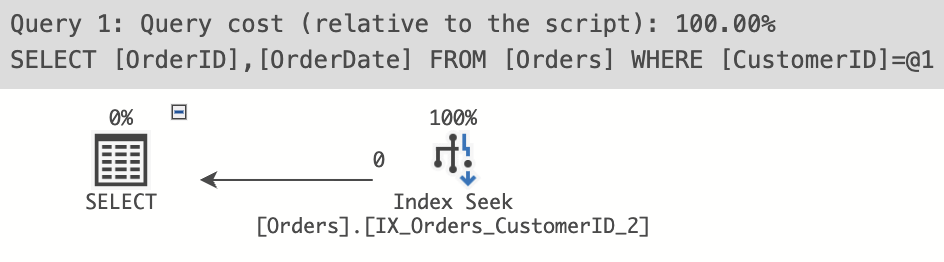
This time SQL Server can use the IX_Orders_CustomerID_2 index to quickly find the OrderDate for all orders from customer 123 without having to perform a key lookup. This is a covered query.
We can include multiple columns with the INCLUDE option. The order of these columns doesn’t impact the performance of queries that use the index.
But Wait! What about the OrderId Column?
You may have noticed that we didn’t include the OrderId column in our nonclustered index, yet it still ended up being a covering index (i.e. it covered all columns in the query, including the OrderId column).
That’s because the OrderId column is the key of the clustered index (in this case, it’s the table’s primary key). When we create a nonclustered index, the key of the clustered index is automatically included in the nonclustered index. This allows SQL Server to navigate efficiently between the nonclustered index and the clustered index to retrieve additional columns from the base table if it needs to.
If a table doesn’t have a clustered index (i.e., it’s a heap), the nonclustered index will store row identifiers (RID) as pointers to the actual data rows. In this case, we would not get the benefit of automatically including a primary key like OrderID, and we would need to explicitly include it in the nonclustered index if we needed it in our query results. Not doing this would result in a RID lookup (which is like a key lookup, but worse).
When to Use the INCLUDE Option
You would choose to include non-key columns in an index when:
- You want to avoid the overhead of key lookups.
- Your query frequently needs to return columns that are not part of the index key.
- The non-key columns are not good candidates for the index key (e.g., because they are not selective or not frequently used in search conditions). Generally, it’s a good idea to design your nonclustered indexes with as few key columns as possible. By this I mean, only those columns used for searching and lookups should be key columns. All other columns that cover the query should be non-key columns. This ensures that the index key is small and efficient, while including all the columns required to cover the query.
- You want to avoid exceeding the index size limitations, which is currently a maximum of 32 key columns and a maximum index key size of 1,700 bytes (16 key columns and 900 bytes prior to SQL Server 2016 (13.x)). The database engine doesn’t consider non-key columns when calculating the number of key columns or index key size.
By including these columns, you reduce the amount of work the query optimizer has to do, potentially speeding up query execution times. However, it’s important to be mindful of the size of the non-key columns, as including large columns in an index can increase the storage size and maintenance costs.