A column store database is a type of database that stores data using a column oriented model.
A column store database can also be referred to as a:
- Column database
- Column family database
- Column oriented database
- Wide column store database
- Wide column store
- Columnar database
- Columnar store
The Structure of a Column Store Database
Columns store databases use a concept called a keyspace. A keyspace is kind of like a schema in the relational model. The keyspace contains all the column families (kind of like tables in the relational model), which contain rows, which contain columns.
Like this:
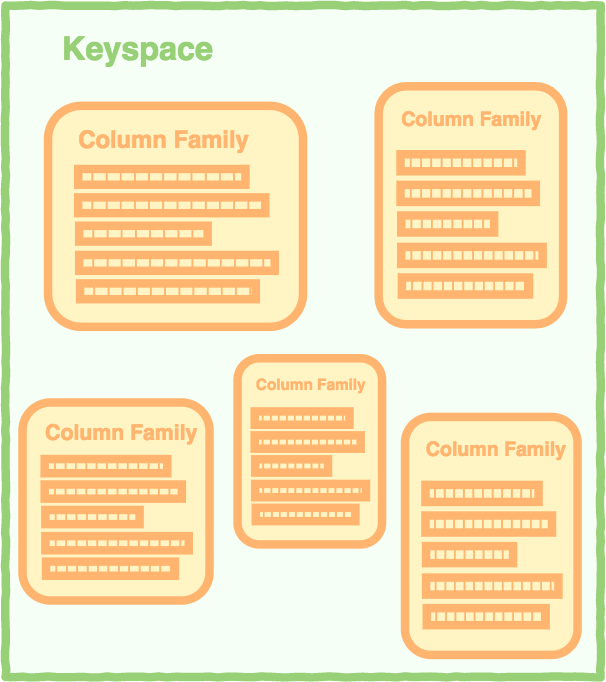
Here’s a closer look at a column family:
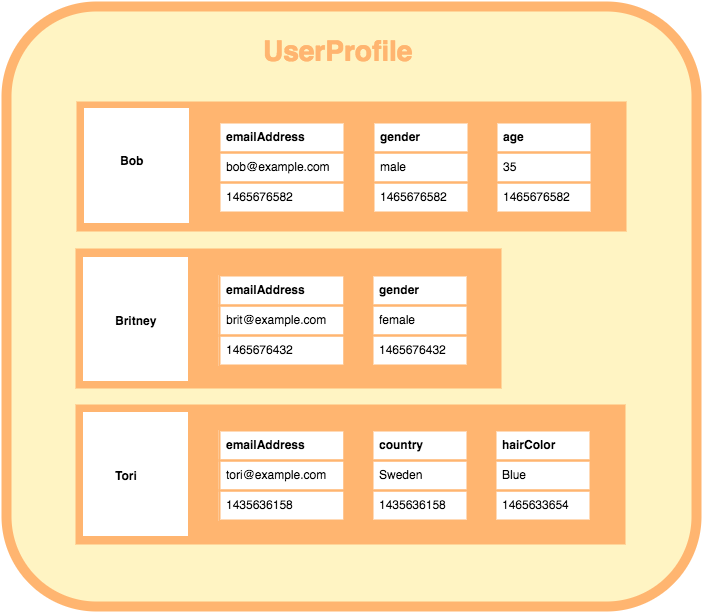
As the above diagram shows:
- A column family consists of multiple rows.
- Each row can contain a different number of columns to the other rows. And the columns don’t have to match the columns in the other rows (i.e. they can have different column names, data types, etc).
- Each column is contained to its row. It doesn’t span all rows like in a relational database. Each column contains a name/value pair, along with a timestamp. Note that this example uses Unix/Epoch time for the timestamp.
Here’s how each row is constructed:
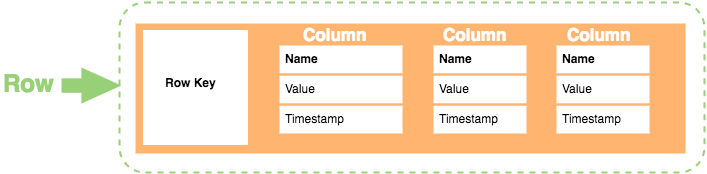
Here’s a breakdown of each element in the row:
- Row Key. Each row has a unique key, which is a unique identifier for that row.
- Column. Each column contains a name, a value, and timestamp.
- Name. This is the name of the name/value pair.
- Value. This is the value of the name/value pair.
- Timestamp. This provides the date and time that the data was inserted. This can be used to determine the most recent version of data.
Some DBMSs expand on the column family concept to provide extra functionality/storage ability. For example, Cassandra has the concept of composite columns, which allow you to nest objects inside a column.
Benefits of Column Store Databases
Some key benefits of columnar databases include:
- Compression. Column stores are very efficient at data compression and/or partitioning.
- Aggregation queries. Due to their structure, columnar databases perform particularly well with aggregation queries (such as SUM, COUNT, AVG, etc).
- Scalability. Columnar databases are very scalable. They are well suited to massively parallel processing (MPP), which involves having data spread across a large cluster of machines – often thousands of machines.
- Fast to load and query. Columnar stores can be loaded extremely fast. A billion row table could be loaded within a few seconds. You can start querying and analysing almost immediately.
These are just some of the benefits that make columnar databases a popular choice for organisations dealing with big data.
NoSQL vs Relational
Some vendors and service providers (such as AWS) refer to columnar databases as NoSQL, citing their differences to the relational database model.
Others however, disagree. Steve Sarsfield (Vice President Product, AnzoGraph) previously worked for Vertica and explains:
From a user perspective, the metadata of a columnar database looks exactly the same as a RDBMS. You perform schema management in much the same way as Oracle. In most cases, it’s 100% SQL compliant and 100 ACID compliant (unlike many NoSQL). NoSQL databases tend to be either Key Value stores or Document Stores. Columnar is neither.