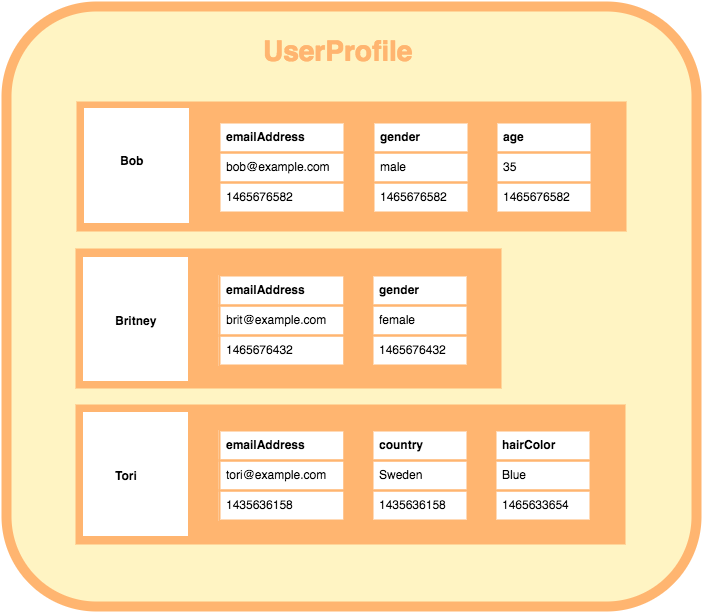
In relational database terms, a row is a collection of fields that make up a record.
The cells in a row run horizontally, and together, contain all data for that record.
A row can contain as many fields as required, each one defined in a different column. There must be at least one column defined in a table before a row of data can be added. The row is the smallest unit of data that can be inserted into a table and deleted from a table.
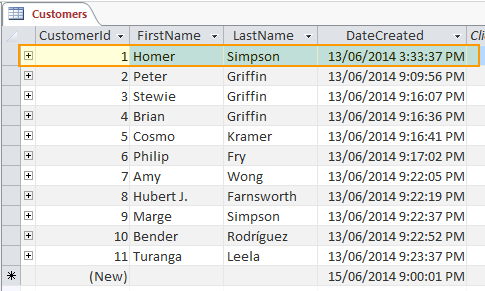
The terms row and record are often used interchangeably, however, some experts point out that there’s a difference between these two terms. They also point out the difference between columns and fields (which are also often used interchangeably).
In any case, teams should decide on a preferred definition for these terms that works for them. If they decide that there’s no difference between “row” and “record”, then they will be able to use the two interchangeably.
Column Store Databases
The above explanation applies to relational databases.
In certain NoSQL database management systems, a row has a slightly different meaning.
In a column store database, each row can contain a different number of columns to the other rows. The columns within each row are contained to that row.
Like this: