Graph databases have been gaining popularity over recent years as a viable alternative to the relational model. Graph databases are particularly well suited to storing connected data – data with lots of interconnected relationships, especially those that run many levels deep.
This article looks at the main differences between graph databases and relational databases.
First, let’s look at the relational database model. Then we’ll look at how the graph model differs from the relational model.
Relational Databases (RDBMS)
An RDBMS uses the relational model as invented by E. F. Codd in 1970. The relational model uses tables (also referred to as relations) to store data.
Any relationship between tables is typically defined when the tables are created (i.e. before any data enters them).
Relational databases have a rigid, predefined structure (known as a schema). The schema is established at the time the database is created. Any data that enters the database must conform to the schema. Therefore, it is of upmost importance that the database is designed appropriately from the start.
Also, future data requirements should try to be anticipated as much as possible, so that the database will be able to accommodate the new requirements if and when the time arises.
Here’s an example of a schema diagram that shows the structure of a relational database:
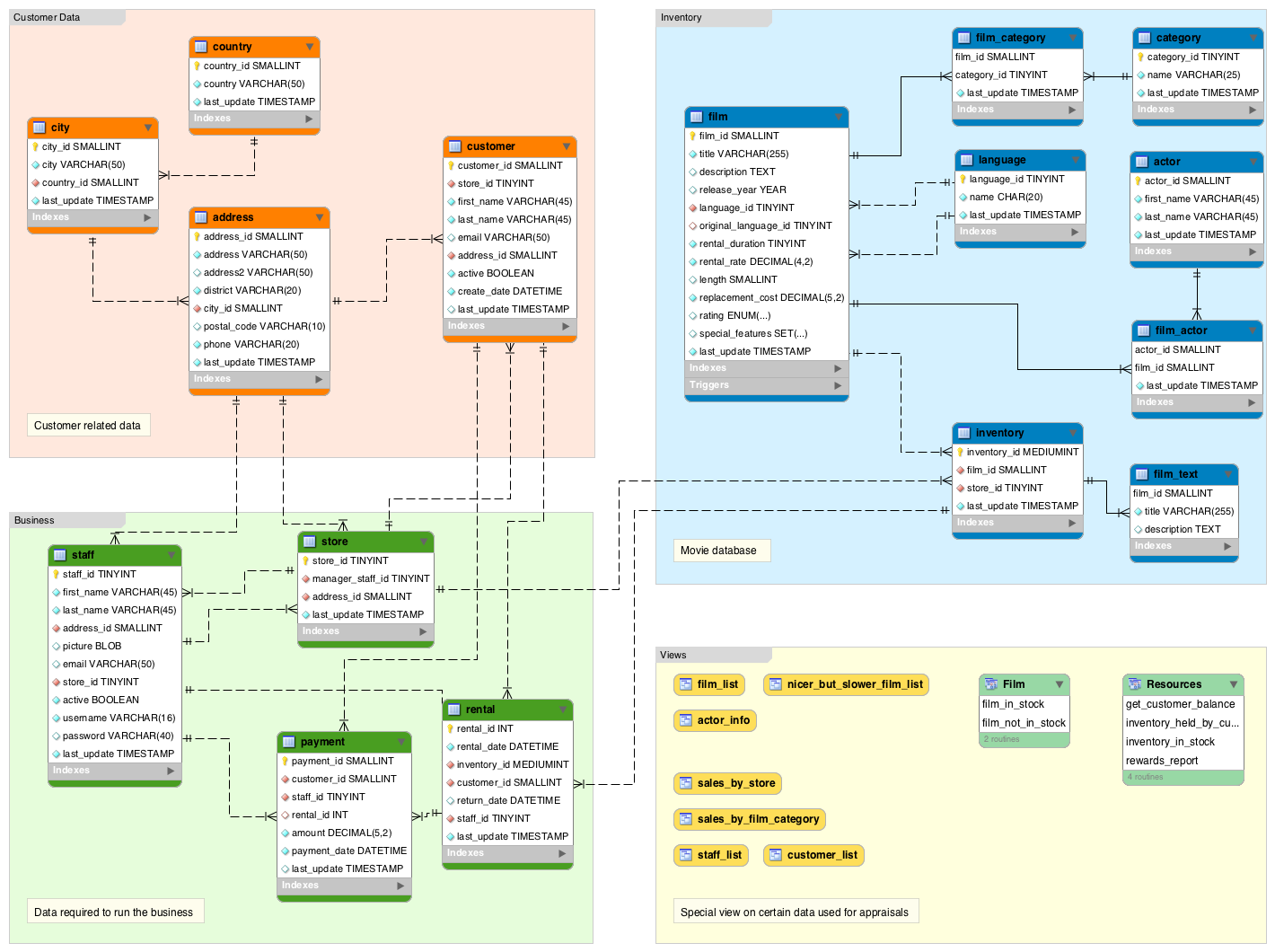
In this diagram, the boxes represent tables. The tables have columns, and each column is assigned a data type.
Any data that is entered into the database, must fit into one of these tables. If it doesn’t fit, then the data won’t enter the database. If the data must enter the database, the database structure (i.e. schema) would need to be changed in order to accommodate the new data requirements.
The dashed lines represent relationships. In a relational database, a relationship exists between tables. So data can only have a relationship with other data if there’s a relationship set up between their respective tables.
Relational databases use primary keys and foreign keys to maintain referential integrity. The foreign key value must match a primary key value in the parent table.
These values are often (but not always) automatically generated numbers. The result of this is that the foreign key values are usually difficult to decipher without running a query that joins the tables on the primary and foreign key so as to extract the human-readable value. Some queries need to perform many joins, and when there’s a lot of data, this can impact on performance.
While relational databases are designed for relational data, one must know which relational data is going to be stored before developing the database.
Graph Databases (GDBMS)
Most graph databases use a different architecture to relational databases, so this opens the model up to a lot of differences. The graph model tends to be more flexible than the relational model.
A graph database uses vertices and edges (typically referred to as nodes and relationships) to store data.
For example, each person in a group could be represented by a node, and their relationship between each other could be represented by a relationship. This is in contrast to the relational model where each person would be stored as a separate record in the same table, with any relationship referencing a separate table.
A key difference between graph databases and the relational model is that graph databases tend to have no fixed schema. Most graph databases are inherently “schema-less”, while some (such as OrientDB) support “schema-full” or “schema-mixed” modes.
But “schema-less” is probably not a completely accurate description. Any schema of a graph database is usually driven by the data. So the schema is constantly evolving as more data is entered.
Here’s an example of a graph database:
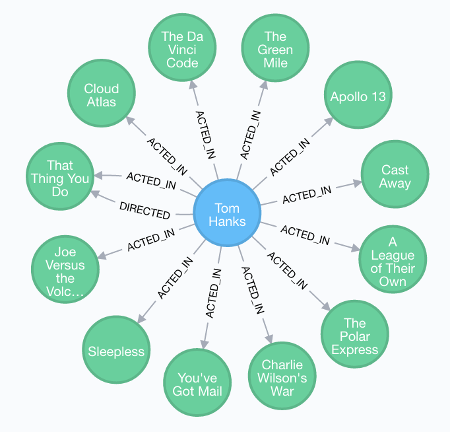
No schema was required in order to get this data into the database. The data itself determines the structure of the nodes and their relationships. Here, the relationships are represented by the arrows.
If a new type of data needed to be added, it could be done so immediately – without needing to update any schema first. For example, if Tom Hanks decides to become a singer and releases an album, we could run some code that adds the album name and have it linked to Tom Hanks. Oh hang on…
The relationships have names, which makes it easy to work out what the nature of the relationship is. The relationships can also have their own properties. So relationships are an integral part of the graph model.
Graph databases are particularly suited to connected data, such as social media, product recommendations, organisational charts, etc.
It could be argued that graph databases are more suited to relationships than relational databases. Graph databases excel when faced with large sets of associative data. Rather than querying a whole table of potentially millions of records, a graph query can concern itself only with the data associated within the specified relationship/s.