The Third Manifesto is a detailed proposal for the future direction of data and database management systems (DBMSs).
Written by C.J. Date and Hugh Darwen, The Third Manifesto can be viewed as a blueprint for the design of future DBMSs, as well as any language designed to interface with them.
The Third Manifesto is generally positioned as a logical progression of the papers that Edgar F. Codd put forward when defining the relational model (beginning with A Relational Model of Data for Large Shared Data Banks in 1970). It does not reject Codd’s relational model, rather it seeks to reinforce it, while also catering for future data requirements.
Furthermore, The Third Manifesto is not to be seen as an “extension” of the relational model. Rather, it is an attempt to clarify that model (and in the process points out why most “relational” DBMSs are not relational at all).
The Third Manifesto also presents a type theory that serves as a basis for a comprehensive model of type inheritance.
The Third Manifesto is primarily aimed towards DBMS vendors – those responsible for designing and producing DBMSs. However, it is also written for the benefit of any database professional interested in furthering their knowledge in the area of relational database management systems. It assumes a good understanding of classical database theory and practice.
What’s the Problem?
Given the popularity of current “relational” and “object relational” DBMSs such as SQL Server, Oracle, MySQL, Microsoft Access, PostgreSQL, etc, you might be wondering, what’s wrong with these systems that would require a whole new blueprint to be developed. And why would we need a new language to interface with them – isn’t SQL enough?
When they wrote their first Manifesto, the authors believed that DBMSs needed to evolve to deal with much more sophisticated kinds of data than they were capable of at the time. They believed that there was a strong need to find a way of extending, dramatically, the range of possible kinds of data we could keep in our databases.
Here’s an example they use to demonstrate.
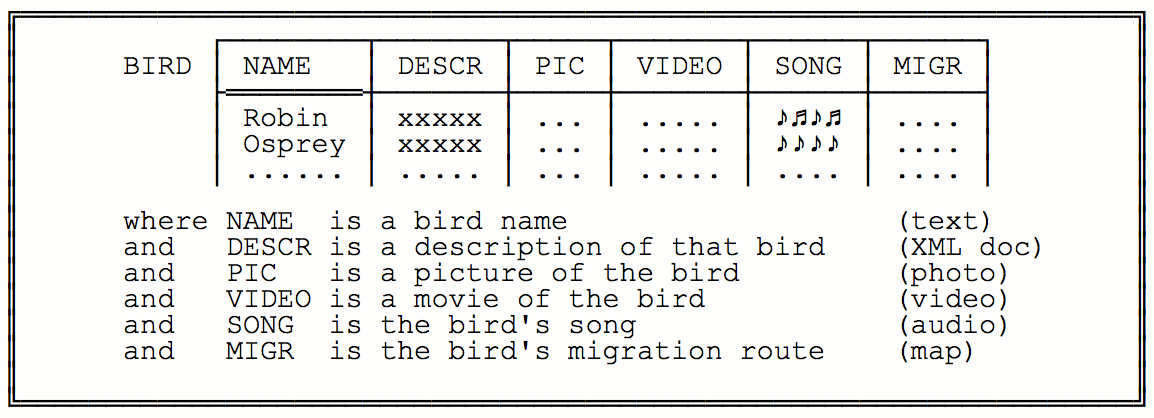
In this case, the database can hold data such as photos, videos, audio clips, and maps.
The Third Manifesto gives an example, where you might want to find information on birds whose migration route includes say Italy. In this case, an SQL version might look like this:
SELECT NAME, DESCR, SONG, VIDEO
FROM BIRD
WHERE INCLUDES ( MIGR, COUNTRY('Italy') )
However, the authors emphasize that this example only uses SQL for reasons of familiarity, and that going forward, a whole new query language should be built.
The Rejection of SQL
One of the most significant assertions of The Third Manifesto is that SQL should be replaced with a different query language, named D. The proposal is that there could be many languages, all qualifying as valid D.
There are many specific reasons for the authors’ outright rejection of SQL, but the overarching reason is that, SQL does not truly adhere to the relational model as proposed by Codd.
No Nulls
For example, SQL allows for nulls, but this is not permissible in the relational model. In the relational model, a table is a set of tuples. Every tuple of every relation contains exactly one value for each attribute of that relation. However, seeing as nulls are not values, any system that permits nulls is in violation of the relational model.
Here’s how the authors of The Third Manifesto put it:
…since (by definition) nulls are not values, the notion of a “tuple” containing nulls is a contradiction in terms. A “tuple” that contains nulls is not a tuple, and a “relation” that contains such a “tuple” is not a relation. Thus, relations never contain nulls.
No Duplicates
A similar case is put forward for SQL’s support for duplicate rows. SQL supports duplicate rows (albeit, only in cases where no key is declared for it via either PRIMARY KEY or UNIQUE).
The Third Manifesto recognizes this as being against the principles of the relational model:
No relation ever contains two or more distinct appearances of the same tuple ( “duplicate tuples”). This property follows because a body is a set of tuples, and sets in mathematics have no duplicate elements. Now, you probably know that SQL tables are allowed to contain duplicate rows, and SQL tables are thus not relations, in general. Please understand, therefore, that in this book we always use the term “relation” to mean a relation—without duplicate tuples, by definition—and not an SQL table. Please note further that relational operations always produce a result without duplicate tuples, again by definition.
History of The Third Manifesto
The Third Manifesto is intended to be an abstract blueprint for the design of a DBMS and the language interface to such a DBMS. It was originally written in the early 1990s due to the authors’ concerns about certain trends they observed in the database industry at that time. In particular, they were concerned about the way in which database vendors were integrating object and relational technologies.
The Third Manifesto was written as a response to two earlier writings, namely:
- The Object-Oriented Database System Manifesto by M. Atkinson, F. Bancilhon, D. DeWitt, K. Dittrich, D. Maier, and S. Zdonik.
- The Third-Generation Database System Manifesto by Michael Stonebraker, Lawrence A. Rowe, Bruce G. Lindsay, James Gray, Michael Carey, Michael Brodie, Philip Bernstein, and David Beech.
The first essentially ignored the relational model, which in Date and Darwen’s view, ruled it out as a serious contender.
The second embraced the relational model, but it did so while appearing to assume that SQL “was (and is) an adequate realization of the relational model and hence an adequate foundation on which to build”.
Therefore, The Third Manifesto was written in an attempt to “correct” the deficiencies of these earlier writings.
The Third Manifesto and related papers, presentations, videos, etc can be found at the thethirdmanifesto.com.