Normalization is the process of organizing a database to reduce redundancy and improve data integrity.
Normalization also simplifies the database design so that it achieves the optimal structure composed of atomic elements (i.e. elements that cannot be broken down into smaller parts).
Also referred to as database normalization or data normalization, normalization is an important part of relational database design, as it helps with the speed, accuracy, and efficiency of the database.
By normalizing a database, you arrange the data into tables and columns. You ensure that each table contains only related data. If data is not directly related, you create a new table for that data.
For example, if you have a “Customers” table, you’d normally create a separate table for the products they can order (you could call this table “Products”). You’d create another table for customers’ orders (perhaps called “Orders”). And if each order could contain multiple items, you’d typically create yet another table to store each order item (perhaps called “OrderItems”). All these tables would be linked by their primary key, which allows you to find related data across all these tables (such as all orders by a given customer).
Benefits of Normalization
There are many benefits of normalizing a database. Here are some of the key benefits:
- Minimizes data redundancy (duplicate data).
- Minimizes null values.
- Results in a more compact database (due to less data redundancy/null values).
- Minimizes/avoids data modification issues.
- Simplifies queries.
- The database structure is cleaner and easier to understand. You can learn a lot about a relational database just by looking at its schema.
- You can extend the database without necessarily impacting the existing data.
- Searching, sorting, and creating indexes can be faster, since tables are narrower, and more rows fit on a data page.
Example of a Normalized Database
When designing a relational database, one typically normalizes the data before they create a schema. The database schema determines the organization and the structure of the database – basically how the data will be stored.
Here’s an example of a normalized database schema:
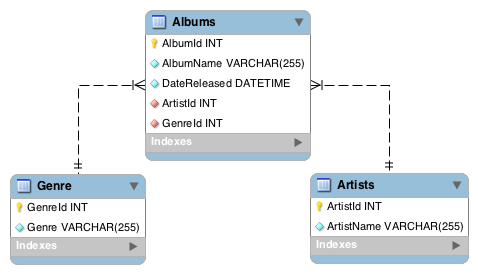
This schema separates the data into three different tables. Each table is quite specific in the data that it stores – there’s one table for albums, one for artists, and another that holds data that’s specific to genre. However, because the relational model allows us to create a relationship between these tables, we can still find out which albums belong to which artist, and in which genre they belong.
If we denormalize this database so that all three tables are combined into one table, we might have a table like this:
| Id | ArtistName | AlbumName | DateReleased | Genre |
| 1 | Iron Maiden | Powerslave | 03-Sep-1984 | Rock |
| 2 | Iron Maiden | Killers | 02-Feb-1981 | Rock |
| 3 | Iron Maiden | Somewhere in Time | 29-Sep-1986 | Rock |
| 4 | Miles Davis | Bitches Brew | 30-Mar-1970 | Jazz |
| 5 | The Wiggles | Big Red Car | 20-Feb-1995 | Childrens |
While this denormalized database can still be useful, it does have its shortcomings.
You’ll notice we have to repeat the artist name for every album an artist has released. We also repeat the genre across multiple albums. This tends to require more storage space than a normalized database. But it can be also troublesome when inserting, updating, or deleting data.
In particular, it can result in the following three anomalies:
- Update anomaly
- If we need to update an artist’s name, we’ll need to update multiple rows. Same with genre. This could result in errors. If we update some rows, but not others, we’ll end up with inaccurate data. This is known as an update anomaly.
- Insertion anomaly
- It’s possible that some artists haven’t yet released any albums. In this case, we can’t add the artist at all – unless we set three fields to null (AlbumName, DateReleased, Genre). This is known as an insertion anomaly. When the artist finally releases an album, we might insert a new row, but in this case, we’ll end up with two rows for that artist – one of which is pretty much useless, and could cause confusion. While we could write scripts in an attempt to deal with this scenario, it’s not an ideal situation, and the scripts themselves could contain errors.
- Deletion anomaly
- If we need to delete an album, we can’t do that without also deleting the artist. If an artist only has one album, and we delete that album, we’ll end up deleting the artist from our database. We’ll no longer have any record of that artist in our database. This is known as a deletion anomaly.
These anomalies are not good for referential integrity (or for data integrity in general).
The User is Unaware of the Normalized Structure
In a normalized database, the data is usually arranged independently of the users’ desired view of that data. This is one of the principles of relational database design.
In fact, E.F. Codd’s 1970 paper A Relational Model of Data for Large Shared Data Banks (which introduced the relational model for the first time) starts with this line:
Future users of large data banks must be protected from having to know how the data is organized in the machine (the internal representation).
So for example, just because a user wants to see a list of albums grouped by artist, this doesn’t mean that the database must arrange the data in that way. Besides, users will usually want to see the data represented in many different ways, depending on the task at hand. The same user might later want to see a list of albums grouped by genre.
Indeed, a user’s query results could look just like the “denormalized” example above, even though the source data was spread across multiple tables.
The user might then run a report that presents the same data in a completely different way. Like this for example:
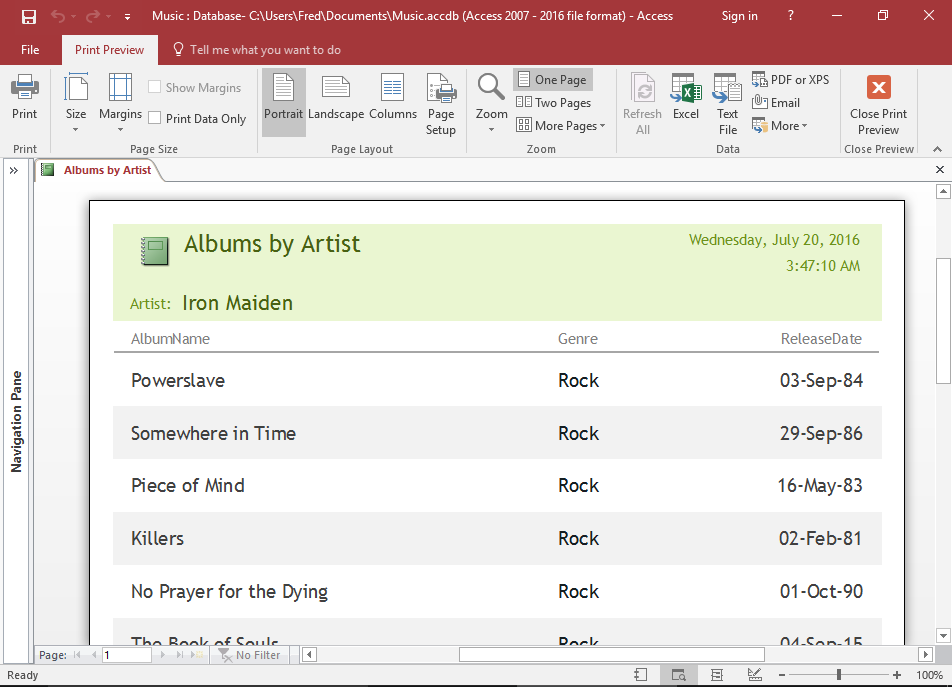
In both cases, the user can view the data exactly as desired, regardless of its normalized structure within the database.
Another benefit of this approach is that it’s possible to make changes to the underlying data structure without affecting the users’ view of that data.
Levels of Normalization
There are various levels of normalization, each one building on the previous level. The most basic level of normalization is first normal form (1NF), followed by second normal form (2NF).
Most of today’s transactional databases are normalized in third normal form (3NF).
For a database to satisfy a given level, it must satisfy the rules of all lower levels, as well as the rule/s for the given level. For example, to be in 3NF, a database must conform to 1NF, 2NF, as well as 3NF.
The levels of normalization are listed below, in order of strength (with UNF being the weakest):
- UNF (Unnormalized Form)
- A database is in UNF if it has not been normalized at all.
- 1NF (First Normal Form)
- A relation (table) is in 1NF if (and only if) the domain of each attribute contains only atomic (indivisible) values, and the value of each attribute contains only a single value from that domain.
- 2NF (Second Normal Form)
- A relation is in 2NF if it is in 1NF and every non-prime attribute of the relation is dependent on the whole of every candidate key.
- 3NF (Third Normal Form)
- A relation is in 3NF if it is in 2NF and every non-prime attribute of the relation is non-transitively dependent on every key of the relation.
- EKNF (Elementary Key Normal Form)
- EKNF is a subtle enhancement on 3NF. A relation is in EKNF, if and only if, all its elementary functional dependencies begin at whole keys or end at elementary key attributes.
- BCNF (Boyce-Codd Normal Form)
- BCNF is a subtle enhancement on 3NF. A relation is in Boyce–Codd normal form if and only if for every one of its dependencies X → Y, at least one of the following conditions hold:
- X → Y is a trivial functional dependency (Y ⊆ X)
- X is a superkey for schema R
- 4NF (Fourth Normal Form)
- A relation is in 4NF if and only if for every one of its non-trivial multivalued dependencies X ↠ Y, X is a superkey—that is, X is either a candidate key or a superset thereof.
- ETNF (Essential Tuple Normal Form)
- A relation schema is in ETNF if and only if it is in Boyce-Codd normal form and some component of every explicitly declared join dependency of the schema is a superkey.
- 5NF (Fifth Normal Form)
- A relation is in 5NF if and only if every non-trivial join dependency in that table is implied by the candidate keys.
- 6NF (Sixth Normal Form)
- A relation is in 6NF if and only if every join dependency of the relation is trivial — where a join dependency is trivial if and only if one of its components is equal to the pertinent heading in its entirety.
- DKNF (Domain-Key Normal Form)
- A relation is in DKNF when every constraint on the relation is a logical consequence of the definition of keys and domains, and enforcing key and domain restraints and conditions causes all constraints to be met. Thus, it avoids all non-temporal anomalies.
3NF is strong enough to satisfy most applications, and the higher levels are rarely used, except in certain circumstances where the data (and its usage) requires it.
Normalizing an Existing Database
Normalization can also be applied to existing databases that may not have been normalized sufficiently, although this could get quite complex, depending on how the existing database is designed, and how heavily and frequently it’s used.
You may also need to change the way the normalization was done by denormalizing it first, then normalizing it to the form that you require.
When to Normalize the Data
Normalization is particularly important for OLTP systems, where inserts, updates, and deletes are occurring rapidly and are typically initiated by the end users.
On the other hand, normalization is not always considered important for data warehouses and OLAP systems, where data is often denormalized in order to improve the performance of the queries that need to be done in that context.
When to Denormalize the Data
There are some scenarios where you might be better off denormalizing a database.
Many data warehouses and OLAP applications use denormalized databases. The main reason for this is performance. These applications are typically used to run complex queries that join many tables together, often returning extremely large data sets.
There may also be other reasons for denormalizing a database, such as implementing certain constraints that could not otherwise be implemented.
Here are some common reasons you might want to denormalize a database:
- Most of the frequently used queries require access to the full set of joined data.
- Most applications perform table scans when joining tables.
- Computational complexity of derived columns requires temporary tables or excessively complex queries.
- You may be able to implement constraints that could not otherwise be implemented (depending on the DBMS).
So, while normalization is usually considered a “must have” for OLTP and other transactional databases, it’s not always considered suitable for certain analytical applications.
However, some database professionals oppose the notion of denormalizing a database, claiming that it’s unnecessary and does not improve performance.
History of Normalization
- The concept of normalization was first proposed by Edgar F. Codd in 1970, when he proposed the first normal form (1NF) in his paper A Relational Model of Data for Large Shared Data Banks (this is the paper in which he introduced the whole idea of relational databases).
- Codd continued his work on normalization and defined the second normal form (2NF) and third normal form (3NF) in 1971.
- Codd then teamed up with Raymond F. Boyce to define the Boyce-Codd normal form (BCNF) in 1974.
- Ronald Fagin introduced the fourth normal form (4NF) in 1977.
- Fagin then introduced the fifth normal form (5NF) in 1979.
- Fagin then introduced the domain key normal form (DKNF) in 1981.
- Carlo Zaniolo introduced the elementary key normal form (EKNF) in 1982.
- Ronald Fagin then teamed up with Hugh Darwen and C.J. Date to produce the essential tuple normal form (ETNF) in 2012.