A database table is a structure that organises data into rows and columns – forming a grid.
Tables are similar to a worksheets in spreadsheet applications. The rows run horizontally and represent each record. The columns run vertically and represent a specific field. The rows and columns intersect, forming a grid. The intersection of the rows and columns defines each cell in the table.
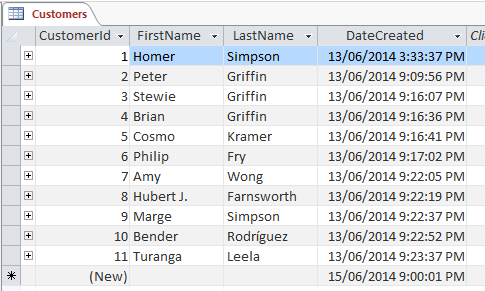
The header cell of a column usually displays the name of the column. The column is usually named to reflect the contents of each cell in that column. For example, a column name of FirstName could be used to reflect that the cells will contain the first name of an individual.
The rows don’t typically have a header cell as such, but often the first column will contain a unique identifier – such as an ID. This field is often assigned as the primary key, as a primary key requires a unique identifier (i.e. the value of this field will be different for each record).
This means that we can identify each record by its ID (or other unique identifier). Therefore, tables can reference records in other tables simply by referring to the record’s primary key value. In this case, the tables have a relationship. This is where the relational part comes from relational database management systems.