There are 3 types of relationships in relational database design. They are:
- One-to-One
- One-to-Many (or Many-to-One)
- Many-to-Many
These are explained below.
One-to-One
A row in table A can have only one matching row in table B, and vice versa.

This is not a common relationship type, as the data stored in table B could just have easily been stored in table A. However, there are some valid reasons for using this relationship type. A one-to-one relationship can be used for security purposes, to divide a large table, and various other specific purposes.
In the above example, we could just as easily have put an HourlyRate field straight into the Employee table and not bothered with the Pay table. However, hourly rate could be sensitive data that only certain database users should see. So, by putting the hourly rate into a separate table, we can provide extra security around the Pay table so that only certain users can access the data in that table.
One-to-Many (or Many-to-One)
This is the most common relationship type. In this type of relationship, a row in table A can have many matching rows in table B, but a row in table B can have only one matching row in table A.

One-to-Many relationships can also be viewed as Many-to-One relationships, depending on which way you look at it.
In the above example, the Customer table is the “many” and the City table is the “one”. Each customer can only be assigned one city,. One city can be assigned to many customers.
Many-to-Many
In a many-to-many relationship, a row in table A can have many matching rows in table B, and vice versa.
A many-to-many relationship could be thought of as two one-to-many relationships, linked by an intermediary table.
The intermediary table is typically referred to as a “junction table” (also as a “cross-reference table”). This table is used to link the other two tables together. It does this by having two fields that reference the primary key of each of the other two tables.
The following is an example of a many-to-many relationship:
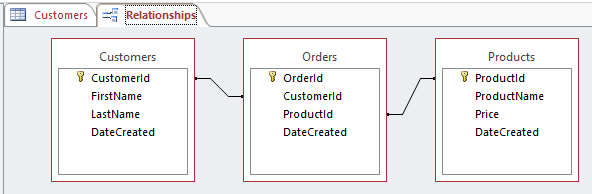
So in order to create a many-to-many relationship between the Customers table and the Products table, we created a new table called Orders.
In the Orders table, we have a field called CustomerId and another called ProductId. The values that these fields contain should correspond with a value in the corresponding field in the referenced table. So any given value in Orders.CustomerId should also exist in the Customer.CustomerId field. If this wasn’t the case then we could have orders for customers that don’t actually exist. We could also have orders for products that don’t exist. Not good referential integrity.
Most database systems allow you to specify whether the database should enforce referential integrity. So, when a user (or a process) attempts to insert a foreign key value that doesn’t exist in the primary key field, an error will occur.
In our example, Orders.CustomerId field is a foreign key to the Customers.CustomerId (which is the primary key of that table). And the Orders.ProductId field is a foreign key to the Products.ProductId field (which is the primary key of that table).